This is the start of a series of blog posts covering the advances of WP5: Cross Media Recommendation.
What is (cross-media) recommendation?
Practically, it is difficult to visit any web page without getting recommendations of one sort or another. There are more welcome recommendations like books you might want to buy or articles to read, and maybe less welcome recommendations like your “personal” selection of ads from some ad-provider. In any case, a recommendation is a selection of items that _is supposed to be_ relevant for the user. To quantify and evaluate this relevance can be tricky, and how this is dealt with in MICO will be part of a later blog post. For now, we will concentrate on how to generate recommendations.
There are two basic types (and of course: hybrids) of recommendation: collaborative filtering (CF) approaches and content based approaches. Building a system that can be unambiguously labelled as one or the other is not always easy, as the concepts are a bit overlapping, but the main ideas are:
- Collaborative filtering (CF): Observing user behaviour and deducing recommendations, without knowing any semantics of the items
- Content based recommendation: Analysing the content of items to guess semantics and deduce recommendations by assuming certain user models
The focus of MICO is media analysis, and hence, the focus of MICO recommendations is on using results from extraction in order to get recommendations – however, if relevant user behaviour data exists, it makes sense to use this too. In fact, such a combination of information sources for recommendations can be key to improve relevance and to bridge media types and application domains.
The MICO recommendation architecture – Bird’s eye view
Recently, we released an updated spec-document for the MICO platform, which reveals a number of details of the recommendation components as well.
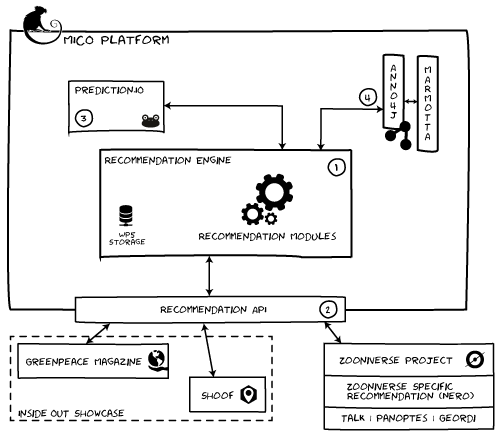
Cross media recommendation system architecture. Generic recommendation tasks are integrated inside the platform and exposed via a recommendation API. This API connects to the showcases, dealing with data import and recommendation queries.
Further details can be found in final spec documents, but let’s have a look at the key points here:
- To retrieve annotations from the knowledge base, the recommendation system uses Marmotta, querying is done by Anno4j. Moreover, the knowledge base can also be used to store recommendation annotations.
- Prediction.io is used for tasks that involve collaborative filtering, i.e., deriving rankings from user behaviour data. Prediction.io is highly configurable, while also providing the essential infrastructure to import and process user behaviour data, and to provide CF results.
- The showcase partners are provided with an API for the input of relevant (user) data.
Recommendation within the specific MICO showcases
Within the inital phase of the project, the scope of the recommendation work package and possible applications was very broad. However, work on media extractors has progrssed substantially, and consequently, priorities on of use case partners IO10 and Zooniverse regarding recommendation have also become more concrete. Hence, in the final year of the MICO project, after a reassessment of recommendation requirements and user stories, we are focusing on implementing and demonstrating recommendations for the following 4 specific cases:
- Editor support for the Greenpeace magazine: For the creation of new articles using WordPress, relevant content (articles, videos) are recommended to the editor for article enrichment.
- Article recommendation for Greenpeace Magazine readers: Results from cross-media analysis are used to increase recommendation quality and increase the click-through rate.
- Shoof video recommendation: Cross-media recommendation is used to recommend / present relevant video segments from the vast amount of available user-generated-content.
- Zooniverse subject recommendation: In Snapshot Serengeti,pictures from camera traps are presented to users for annotation. Cross-media recommendation is used to provide the appropriate “mix” of images for users, to increase user motivation, after considering recent findings about what actually motivates users.
More information on the implementation of recommendation will be covered in further blog posts. The next blog post will describe how Docker is used to encapsulate all dependencies of prediction.io and get a stable recommendation provider inside the platform.
You must be logged in to post a comment.