One of the core parts of the MICO project will be the MICO platform, an environment that will allow to analyse “media in context” by orchestrating a set of different analysis components that can work in sequence on content, each adding their bit of additional information to the final result. Analysis components can e.g. be a “language detector” (identifying the language of text or an audio track), a “keyframe extractor” (identifying relevant images from a video), a “face detector” (identifying objects that could be faces), a “face recognizer” (assigning faces to concrete persons), an “entity linker” (assigning objects to concrete entities) or a “disambiguation component” (resolving possible alternatives be choosing the more likely given the context).
This post gives an introduction into the initial architecture of the MICO platform. Requirements The content that will be analysed in the MICO platform is generally “multimedia” and therefore can be very diverse, ranging from simple HTML pages with images to long video streams in high quality with large amounts of data. Equally diverse are the kinds of analysis that will be performed on this content – some being comparably simple, others requiring considerable computational power. From this context, we derived the following high-level requirements for the platform:
- content items can be large, so it should be possible to move the computation to the data instead of moving the data to the computation; simply sending content to a web service (as is done in other analysis services) is therefore not feasible
- content items can be composite, i.e. consist of a collection of related elements like a textual document with embedded images or videos; therefore, the platform needs to provide a container format for processing content items
- the platform needs to provide orchestration of analysis components, as analysis components are usually very specialised on certain tasks and need to be called independently, but in the right order
- access to content item metadata must be in a uniform, standardised way (through SPARQL queries), because independent analysis components cannot rely on proprietary representation formats
- the platform API for analysis components must be accessible from Java and C++, because existing analysis components are mostly implemented in those two languages and need to be integrated without too much additional effort
Architecture As a result of these requirements, the initial architecture of MICO is designed as a distributed, service-oriented architecture depicted in the following diagram: 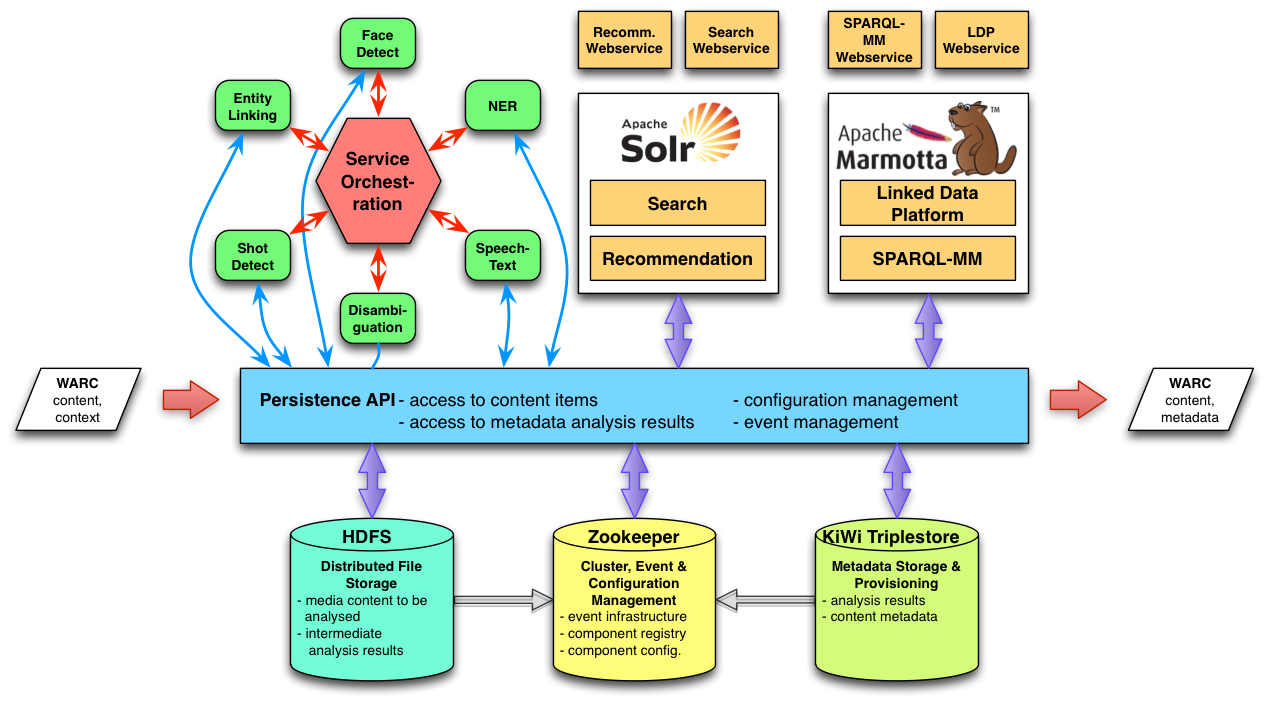 Analysis services and other applications access the platform through a common Persistence API, made available in Java and C++. Content to be analysed is represented in a container format called “Content Item” and can consist of multiple binary content parts as well as RDF graphs for the representation of any kind of metadata (analysis results, orchestration and execution data, provenance metadata). Behind the scenes, the following components provide the necessary functionality:
Analysis services and other applications access the platform through a common Persistence API, made available in Java and C++. Content to be analysed is represented in a container format called “Content Item” and can consist of multiple binary content parts as well as RDF graphs for the representation of any kind of metadata (analysis results, orchestration and execution data, provenance metadata). Behind the scenes, the following components provide the necessary functionality:
- Apache Marmotta with its KiWi triplestore provides metadata storage for content items. Each content item will have its own named graph to represent metadata.
- Apache Camel (or Zookeeper) for event communication between components and execution of an analysis process.
- Apache HDFS (or another distributed file system) for representation of binary content of content items; using a distributed file system simplifies running the computation where the data is located.
Execution Plans An intelligent orchestration component takes care of planning the execution of the analysis process for a given content item based on the analysis goals and available data. Analysis services can register with the platform, state their input requirements and outcomes, and are then considered in execution planning by the orchestration component. The following diagram illustrates how a possible execution plan could look like: 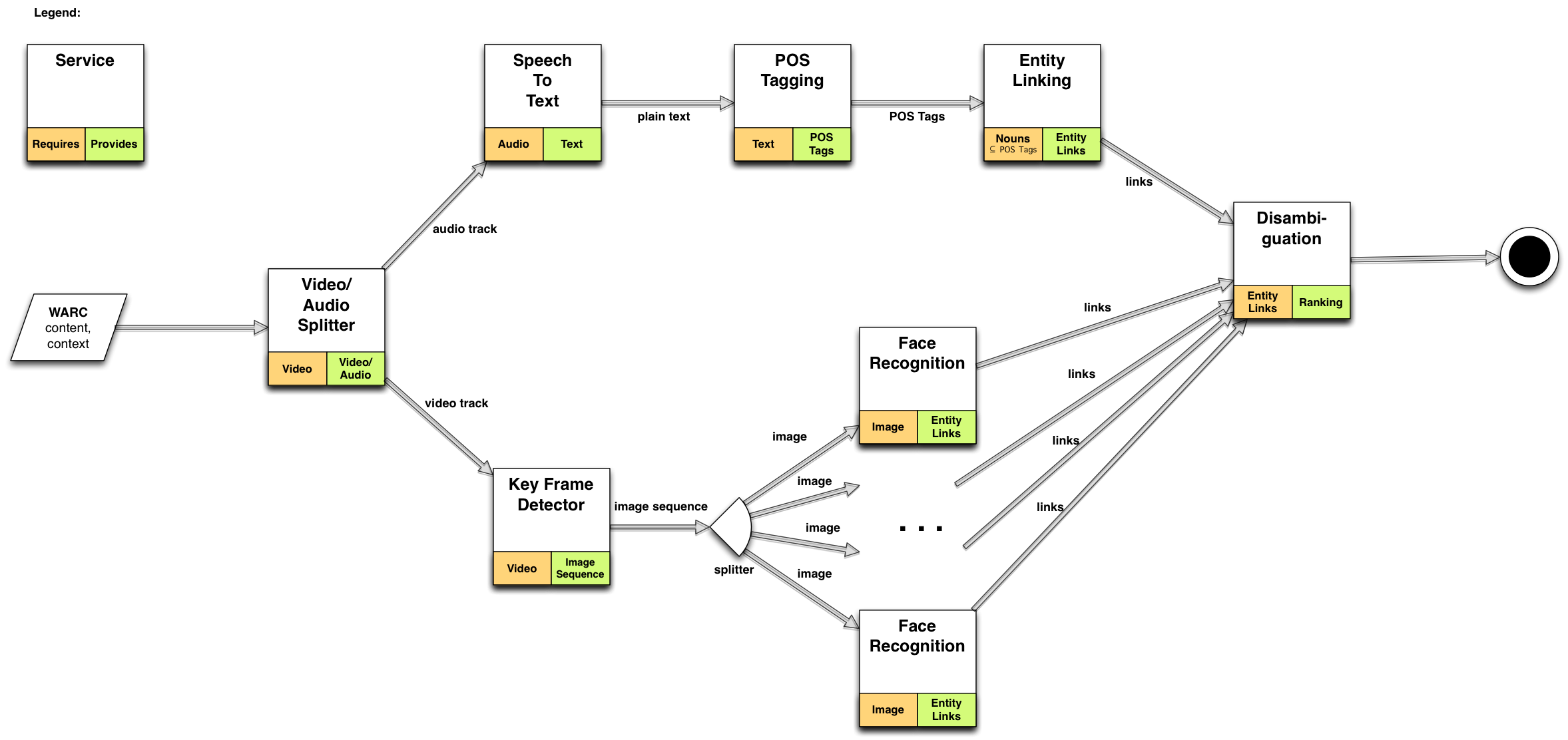 When a content item is injected into the platform, the orchestration service first takes care of the execution planning. In this case, it recognizes that the input is a video file and that the user wants to identify persons. The first component in the execution plan is a video/audio splitter. The audio part is then forwarded to a speech-to-text component for further text processing, while the video part is forwarded to a keyframe detector for later face detection and recognition. After the (possibly parallel) analysis components have finished, a disambiguation component tries to remove inconsistencies between the outcomes of the different components. The resulting data is then published in RDF for other applications to consume.
When a content item is injected into the platform, the orchestration service first takes care of the execution planning. In this case, it recognizes that the input is a video file and that the user wants to identify persons. The first component in the execution plan is a video/audio splitter. The audio part is then forwarded to a speech-to-text component for further text processing, while the video part is forwarded to a keyframe detector for later face detection and recognition. After the (possibly parallel) analysis components have finished, a disambiguation component tries to remove inconsistencies between the outcomes of the different components. The resulting data is then published in RDF for other applications to consume.
Implementation The platform outlined above is currently implemented in Java and C++. A first initial Open Source release with some sample analysis components is planned for October 2014. Stay tuned, we’ll keep you updated here on the progress we make. 😉
You must be logged in to post a comment.